
DeepSeek 的团队真是鬼才,越来越佩服。昨天,他们开源了一个 3B 大小的 DeepSeek-OCR 模型,以及一篇对应的论文。
论文的标题,很多懂行的人一看,都会忍不住连拍大腿:

翻译成中文是:DeepSeek-OCR,上下文的光学压缩。
简单来说,这次 DeepSeek 醉翁之意不在酒,他们并不是奔着更好的 OCR 模型去的,而是试图通过使用视觉模态作为文本信息的有效压缩媒介,来解决 LLM 中的长上下文挑战。
举个简单的例子,当给 LLM 塞一个 10 万以上 Token 的文档,我们能明显感觉到响应速度越来越慢。
怎么应对过大的上下文,这是近几年业界的难题之一。但大家都很清楚,有更大的 Context,这对于实际应用来说有很大的好处。
比如对于 Coding 类的模型而言,更大的上下文意味着模型能够更好理解业务。毕竟大家写代码,很多时候都是在一个大的 Codebase 中做局部的工作。如果模型能够充分理解代码库,也就意味着续写可以更加准确。
当我们往一个大语言模型里硬塞十几万 token 的文档时,它扛不住的原因,其实是架构层面的数学问题。
Transformer 的注意力机制要让每一个 token 都和其他所有 token 交互一次,也就是说计算量是 N² 级别的。
举个例子,当输入是 1 万 token 时,模型需要处理 1 亿次交互,当输入变成 10 万 token 时,这个数就变成了 100 亿次交互。
这会直接导致:延迟变高(推理时间慢)、显存爆炸(中间矩阵太大)、成本飙升(token 费用线性增长)等一系列问题。
所以,长上下文 一直是语言模型最难啃的骨头之一。
DeepSeek 团队提出了一个非常大胆的假设:
“如果文字太多处理不了,那干脆把它变成图像。”
与其让模型去逐字理解,不如先把文本渲染成图片,再用视觉编码器(Vision Encoder)去看这张图。
为什么这样做能压缩信息?因为视觉 token 的信息密度更高。
一段 10 万 token 的文字,如果转成图片,也许只需要几百个视觉 token 就能表达;并且每个视觉 token 不仅包含文字内容,还包含排版、结构、空间关系等额外信息。
也就是说,在几乎不损失语义的情况下,模型可以用少得多的 token 来处理更长的内容。
想起上高中的时候,我曾经听过一个快速记忆的课。当时老师说,快速记忆的秘诀就是把信息视觉化,以及使用比喻。
举个例子,诗词的文字很难记忆,但如果我们能在脑海中,把句子转化为画面,那就会容易很多。
比如王安石的这句诗,我现在都记得非常清楚:茅檐长扫净无苔,花木成畦手自栽。很简单,我脑海中,就是把它对应到我们家的小院里的画面。
所以,人类在处理记忆时,其实也会进行类似的光学压缩。我们不会逐字记住所有内容,而是记住画面和结构。
你可以想想,去年春节时你在干嘛?是不是脑海中也是几个模糊的画面。
DeepSeek 团队发现,当文本被转换成图像后,模型在只使用原本十分之一的 token 情况下,依然能实现几乎无损的识别;即便压缩到二十分之一,仍保留约六成的准确度。
这意味着,视觉不只是让模型看懂图片的手段,而被用来承担信息压缩与记忆管理的角色。
更有意思的是,他们把这种机制和人类的记忆衰减曲线做了类比。
在视觉世界里,物体离我们越远,越模糊;在人类记忆里,时间越久远,细节越模糊。
DeepSeek 直接把这两种现象统一到一个体系里,通过持续降低旧图像的分辨率,让模型在视觉空间中忘记过去的细节。
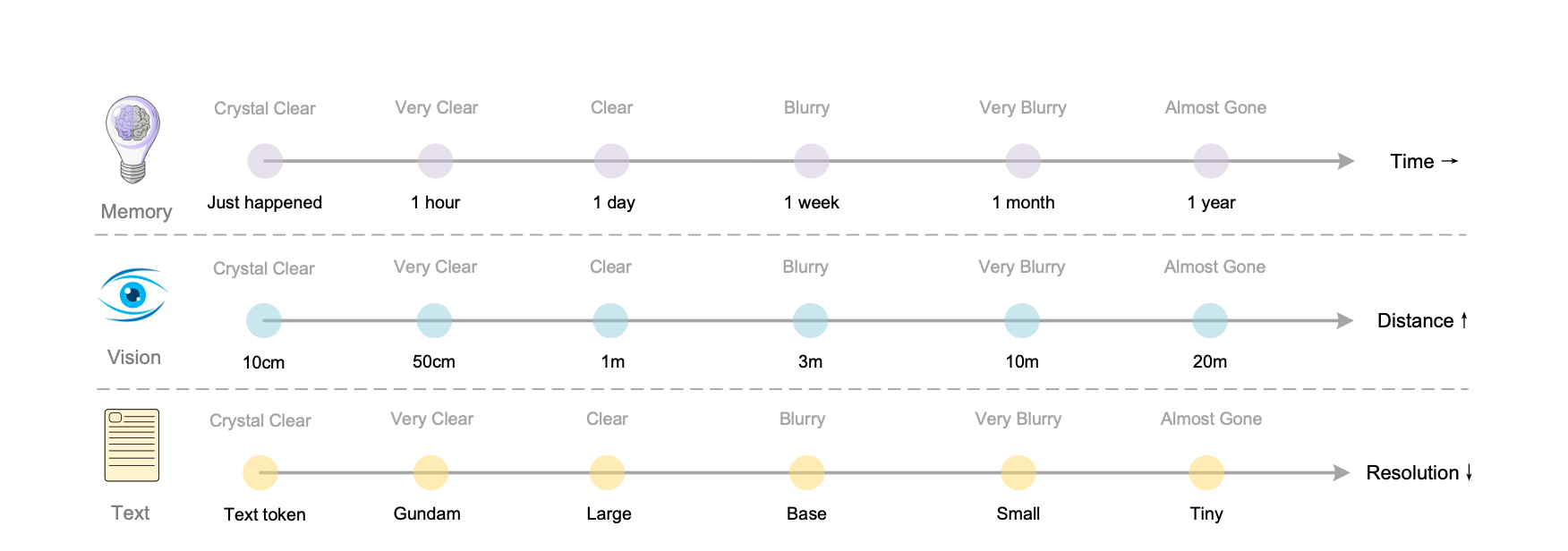
于是,一个新的记忆机制就此诞生。
最近的信息保持高分辨率,语义完整、细节清晰;较远的信息逐渐被模糊、压缩、简化,但核心概念仍在;再往后的信息,则以极低的视觉密度留存在背景中,像记忆深处的一层影子。
这种结构让模型的上下文不再是平面的,而是立体的。它不再一次性处理十几万 token 的巨量信息,而是像人一样,把时间轴拉长:重要的记住,不重要的淡出。
DeepSeek 甚至提出,这种视觉压缩机制或许能应用到对话系统中。在多轮对话中,模型可以通过光学压缩的方式折叠旧对话内容,让过去的上下文以更低的计算成本被保留,从而在理论上实现无限上下文的架构。

我们一直以来,都习惯用文字去描述世界。但仔细想想,文字其实只是思想的中间层。
它把概念铺展开,变成二维的符号,靠视觉去读取,再由大脑重新组织成画面与意义。
DeepSeek 这次做的事,正是在跳过这层冗余,把信息重新折叠回视觉。
当模型直接从图像中理解内容,文字就不再是唯一的载体。它变成了一种可以被压缩、被替换的表达形式。
这其实是在重新思考,数字世界里的文字究竟是什么。
也许我们不该再执着于让模型处理更多的 token,而是去探索更高维度的表达方式,一种能同时保留结构、空间和语义的语言,一种更接近人类感知的视觉语言。








评论 (0)