
今天,百度悄悄发布并开源了一款多模态文档解析模型:PaddleOCR-VL。
我看的第一眼,注意力全被它的参数量吸引了,0.9B。
这么小的参数量,意味着它对算力的要求极低,我感觉扔到手机上都能跑得动。
这对于很多想在本地环境,或者资源受限的设备上玩AI的朋友来说,简直是福音。
我之前做过不少AI知识库的业务,也用过很多OCR工具,那些OCR或多或少都会有一些问题。
要么出现阅读顺序混乱。在处理多栏排版的报纸、论文或杂志的时候,会把不同区块的文字拼接在一起,导致提取出的内容逻辑不通,就没法用。
要么表格解析一塌糊涂。一个清清楚楚的表格,它能给你识别成一堆丢掉结构的零散文字,还得你手动去重新整理。
另外就是公式识别,经常把各种数学公式,识别成一堆无意义的乱码。。。
现在,对于任何一个新出的OCR工具,我都是抱着期待又怀疑的态度。
于是,我很快就上手试用了PaddleOCR-VL。
没想到,这个0.9B的小鼻嘎,还挺不错。
比如我找了一张9月开的发票,上传给它识别
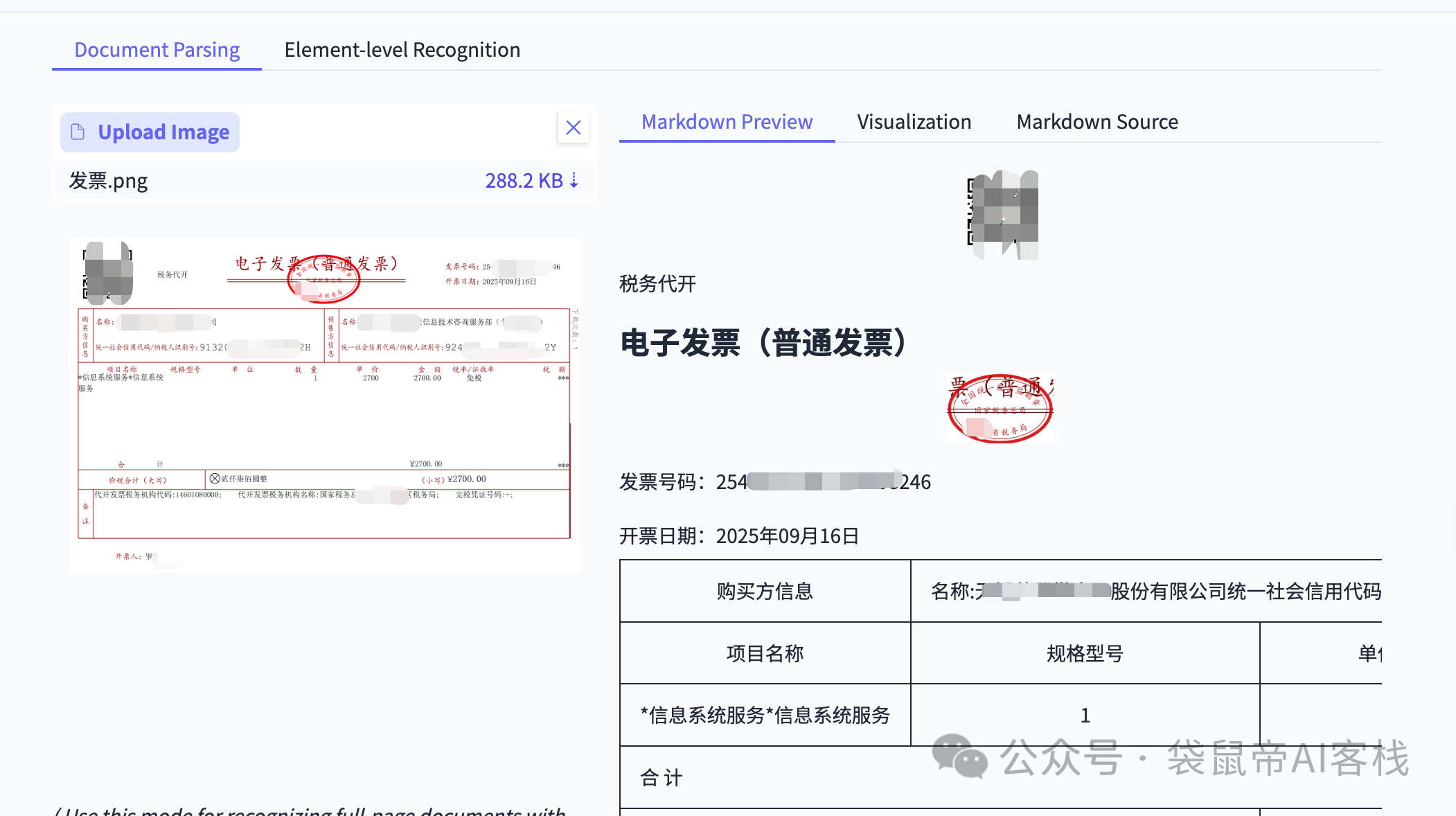
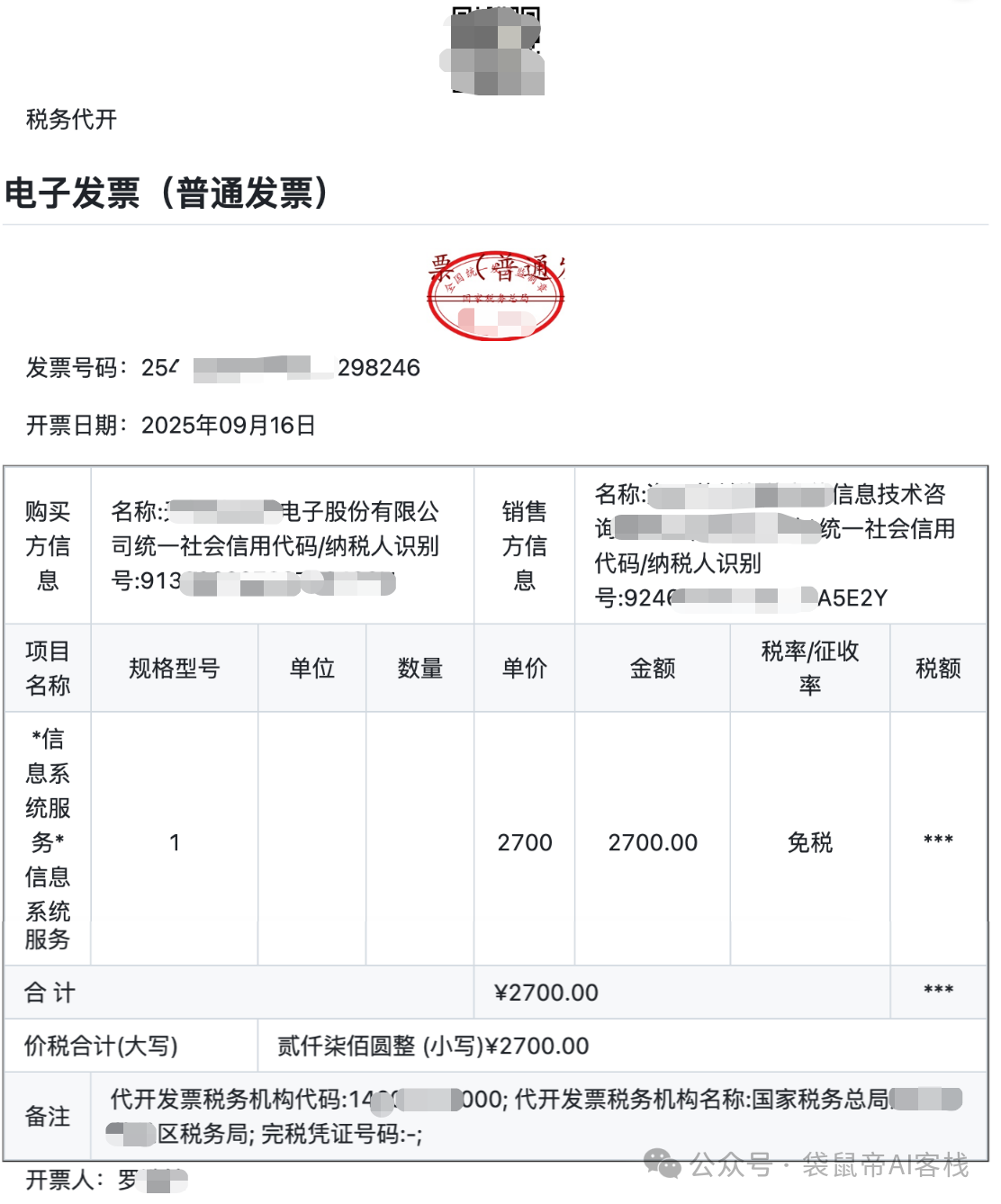
结果,它完成的相当不错,不仅精准识别了上面的文字、数字,还给我输出了一个表格。
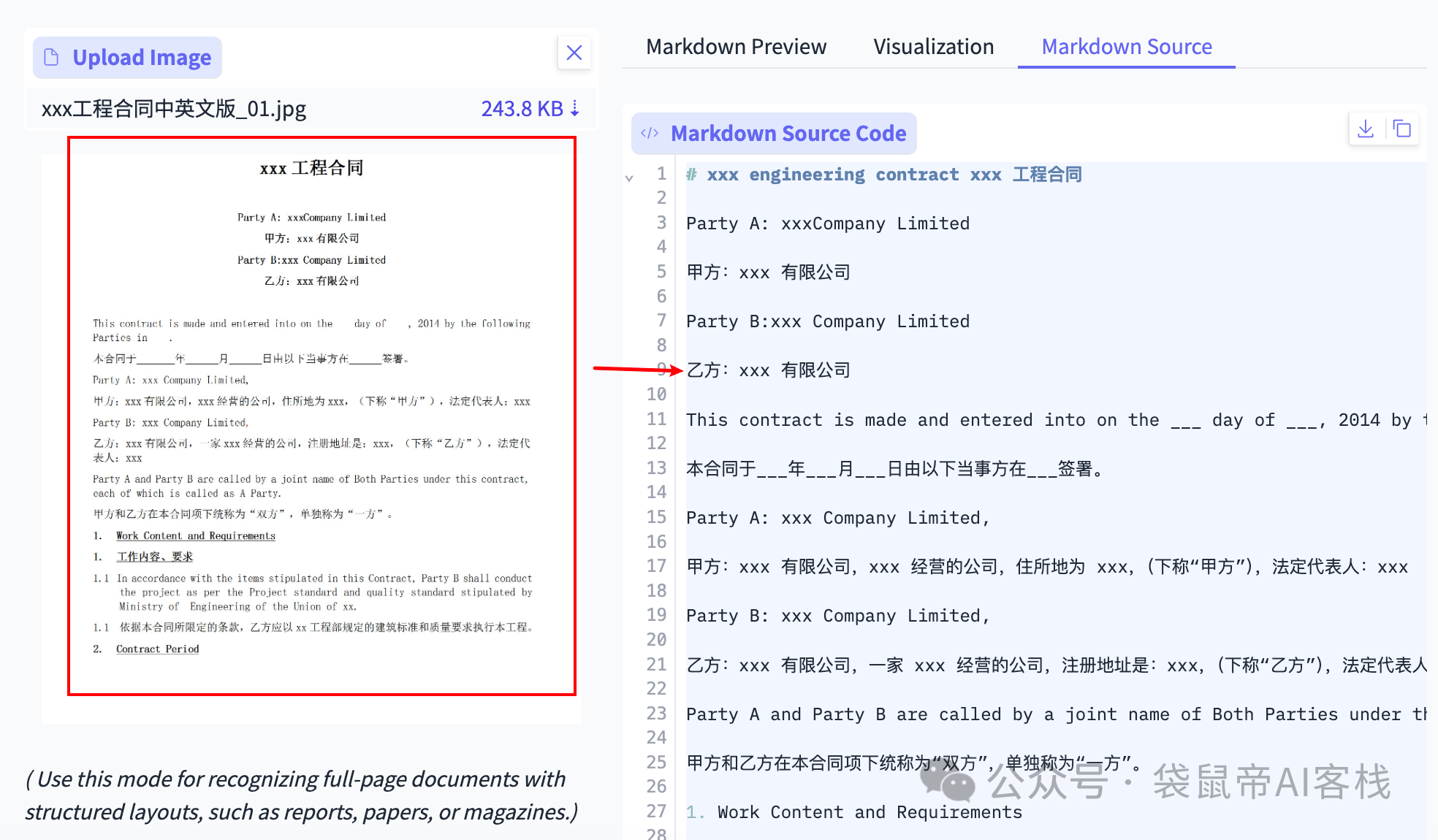
像这种双语合同也是轻松识别

我又找了一些一些柱状图、折线图让它识别:
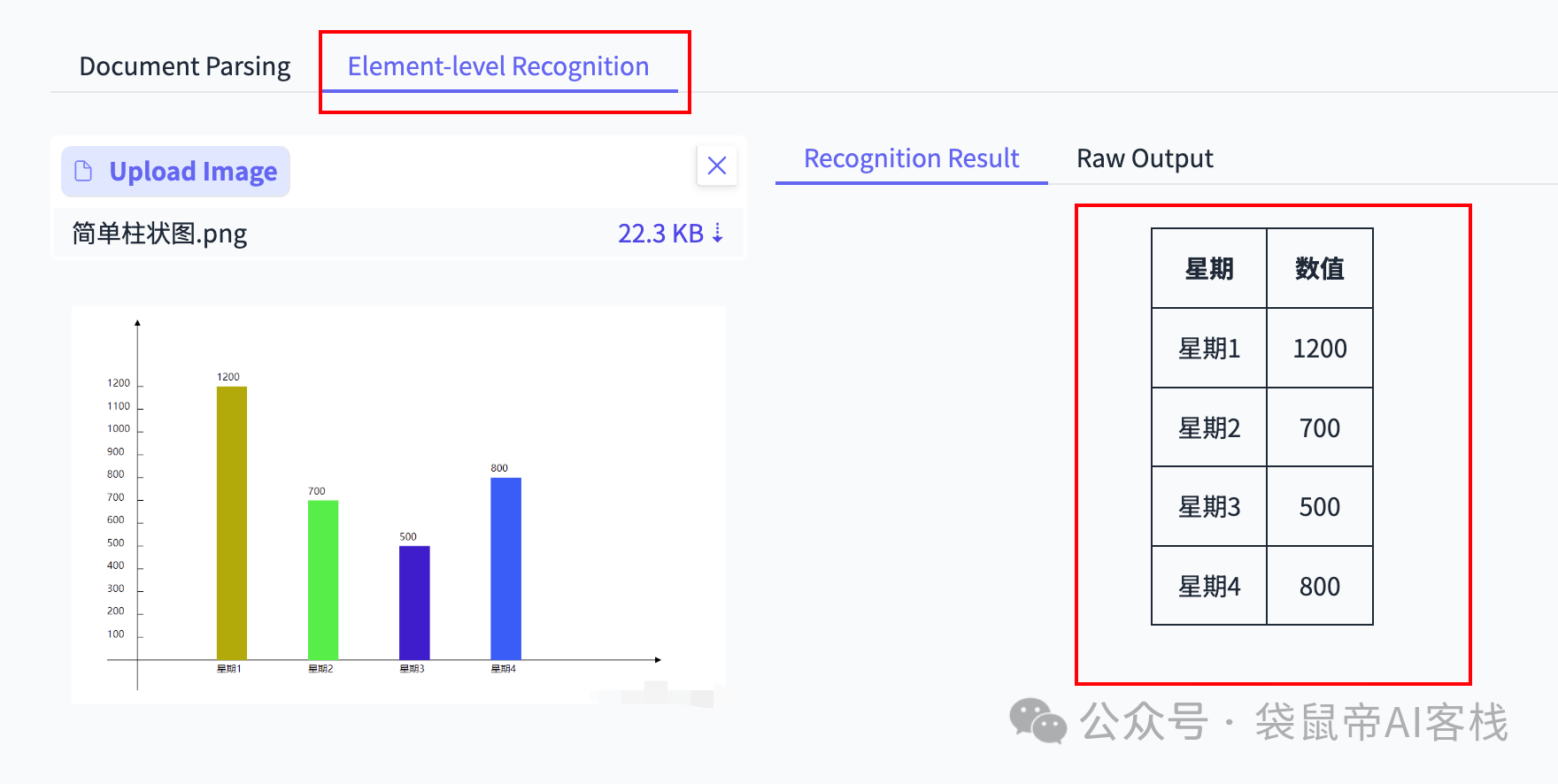
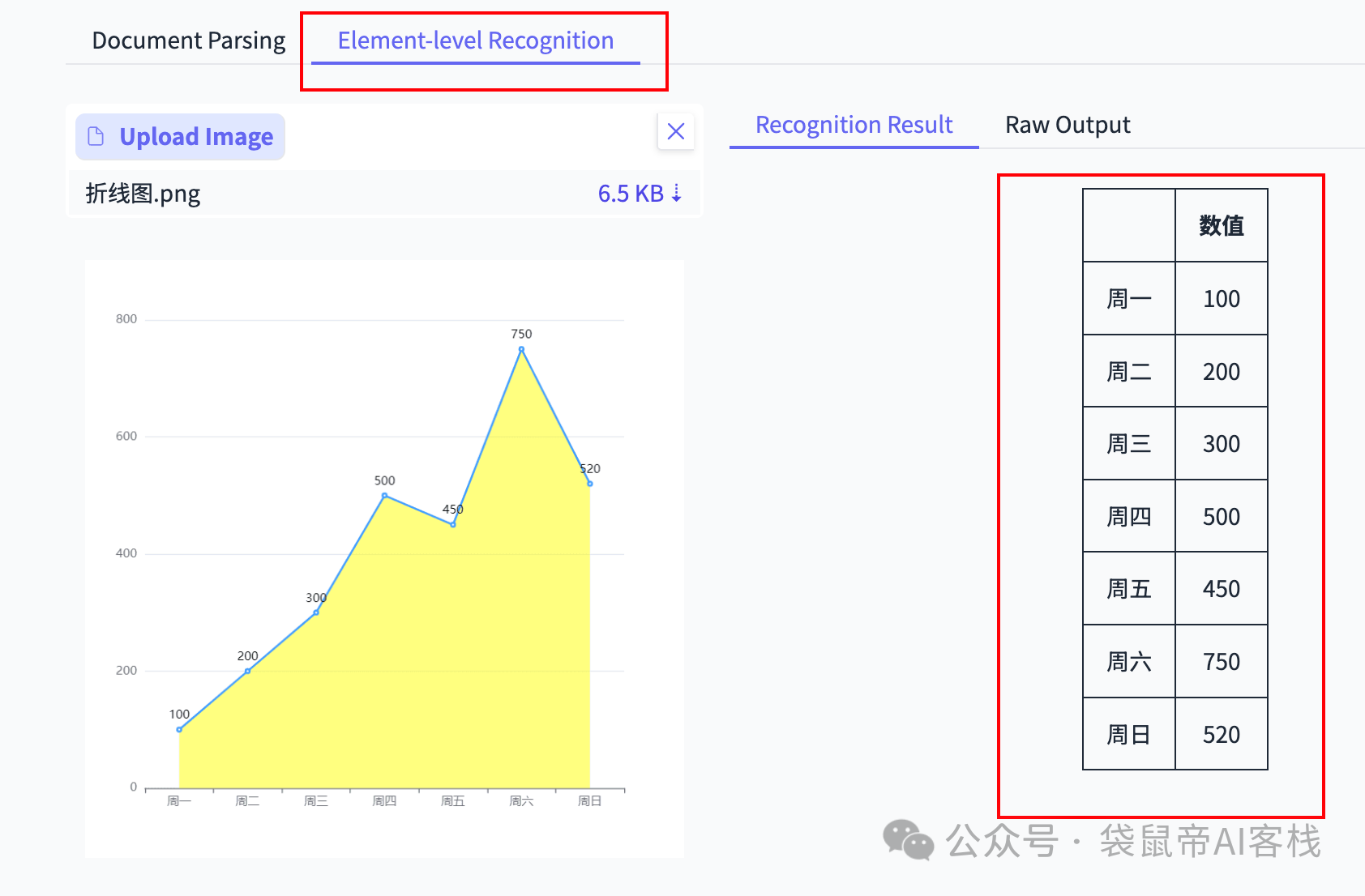
他竟然能识别出图表数据的关联关系,并转成一个markdown格式的数据
这两个小测试,瞬间就勾起了我的兴趣。我决定,得再给它上上强度。
不过在这之前,还是先给大家介绍一下PaddleOCR-VL到底是个啥?
我查了一下:
这款模型,来自百度飞桨的PaddleOCR团队。
这个团队,在OCR领域,相当强劲。
他们的PaddleOCR开源项目,在GitHub上是中国唯一一个Star数超过50k的OCR项目(现在57.2K了),累计下载量超900万,被超过5.9k开源项目直接或间接使用,绝对是业内的老大哥。
https://github.com/PaddlePaddle/PaddleOCR
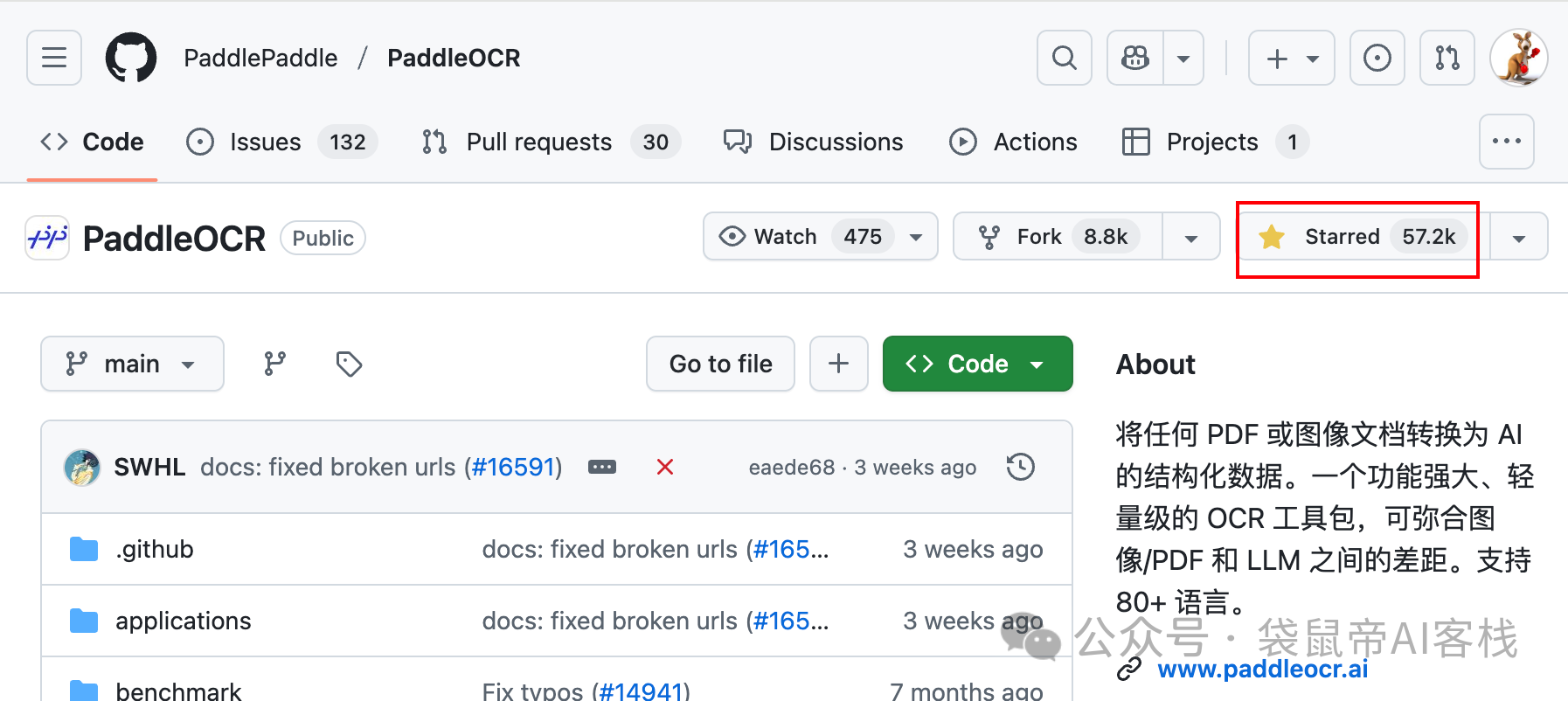
这次的PaddleOCR-VL,可以看作是他们把OCR技术和最新的大模型能力结合起来的产物。
PaddleOCR-VL基于ERNIE-4.5-0.3B的语言模型训练而来,是文心4.5的最强衍生模型。
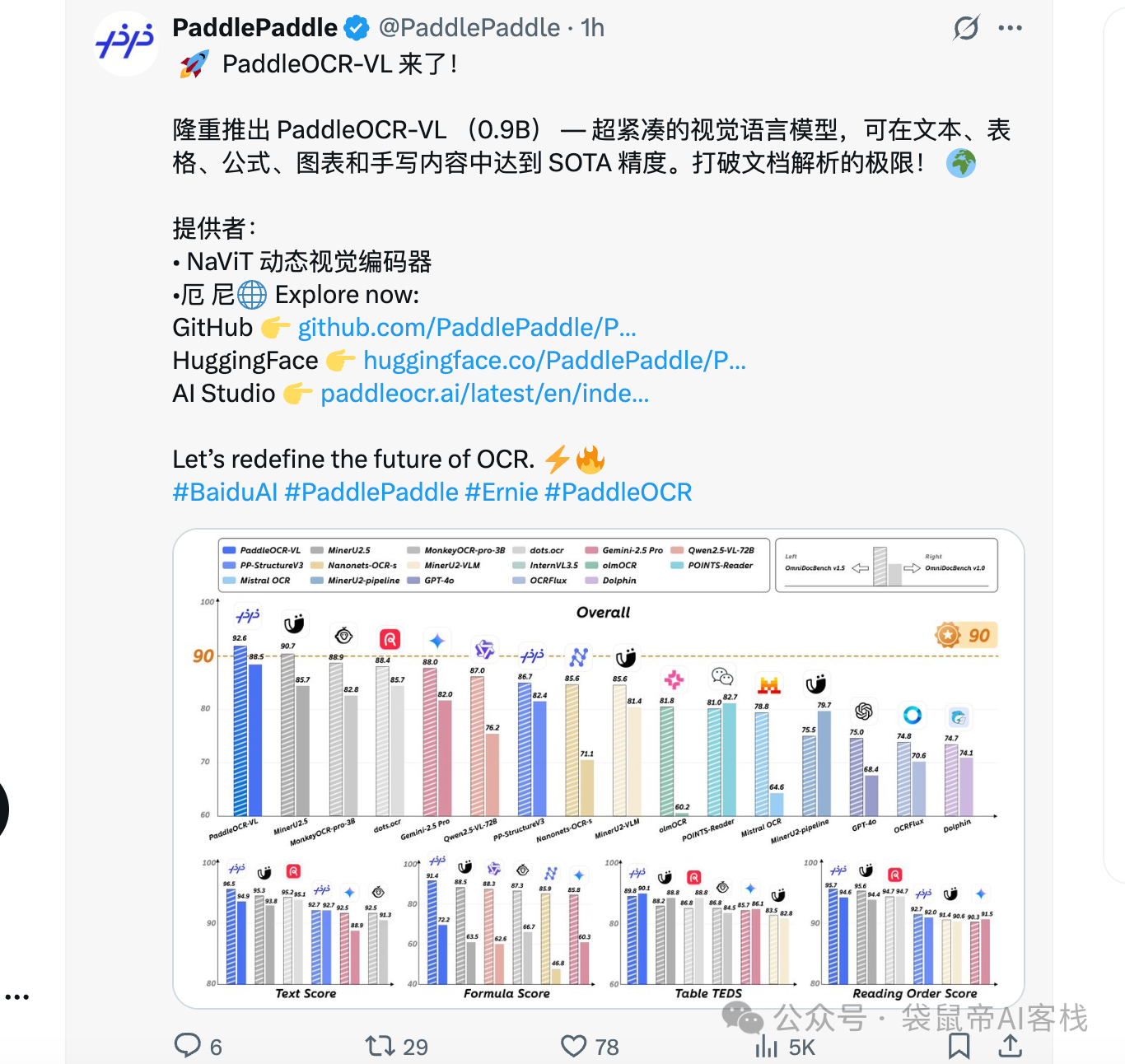
在最新的OmniDocBench V1.5这个国际权威榜单上,直接屠榜了。
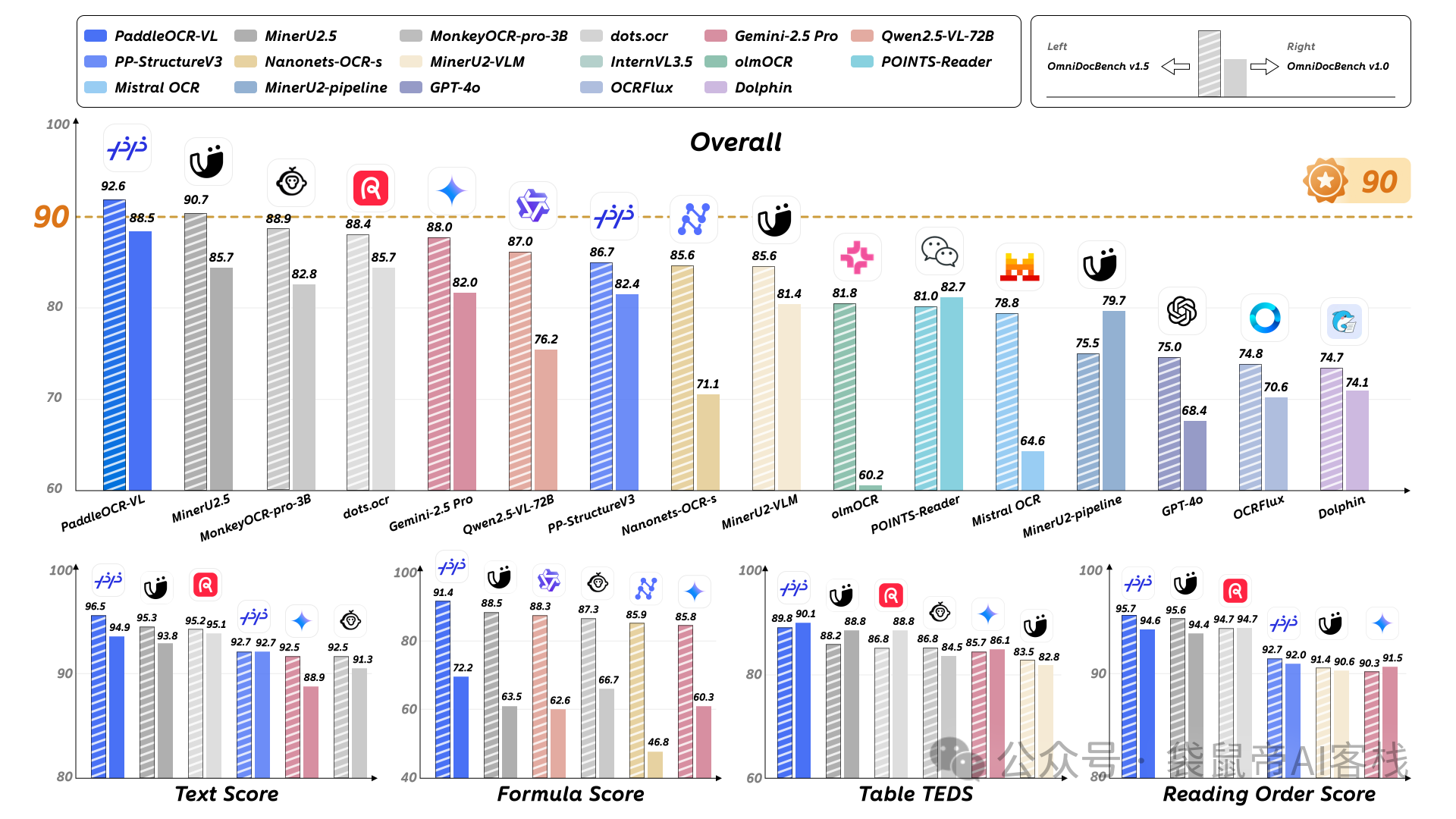
把GPT-4o,Gemini-2.5 Pro这些国际大厂的顶级多模态模型,都甩在了后面。
在文本识别,公式识别,表格理解,阅读顺序这四个OCR的核心能力上,也全部拿了第一。
OmniDocBench V1.5是目前国际上最系统、最具代表性的文档视觉语言理解基准之一,由OpenDataLab联合清华大学、阿里达摩院、上海人工智能实验室等多家机构共同建设。
覆盖了学术论文、财务报表、手写笔记等九大类真实世界里最复杂的文档场景,是目前行业里公认最全面、最难的文档理解评测基准之一
像GPT-4o、Gemini-2.5 Pro、Qwen2.5-VL这些国际主流的顶级模型,都把它作为官方的评测标准,来证明自己的文档处理能力。
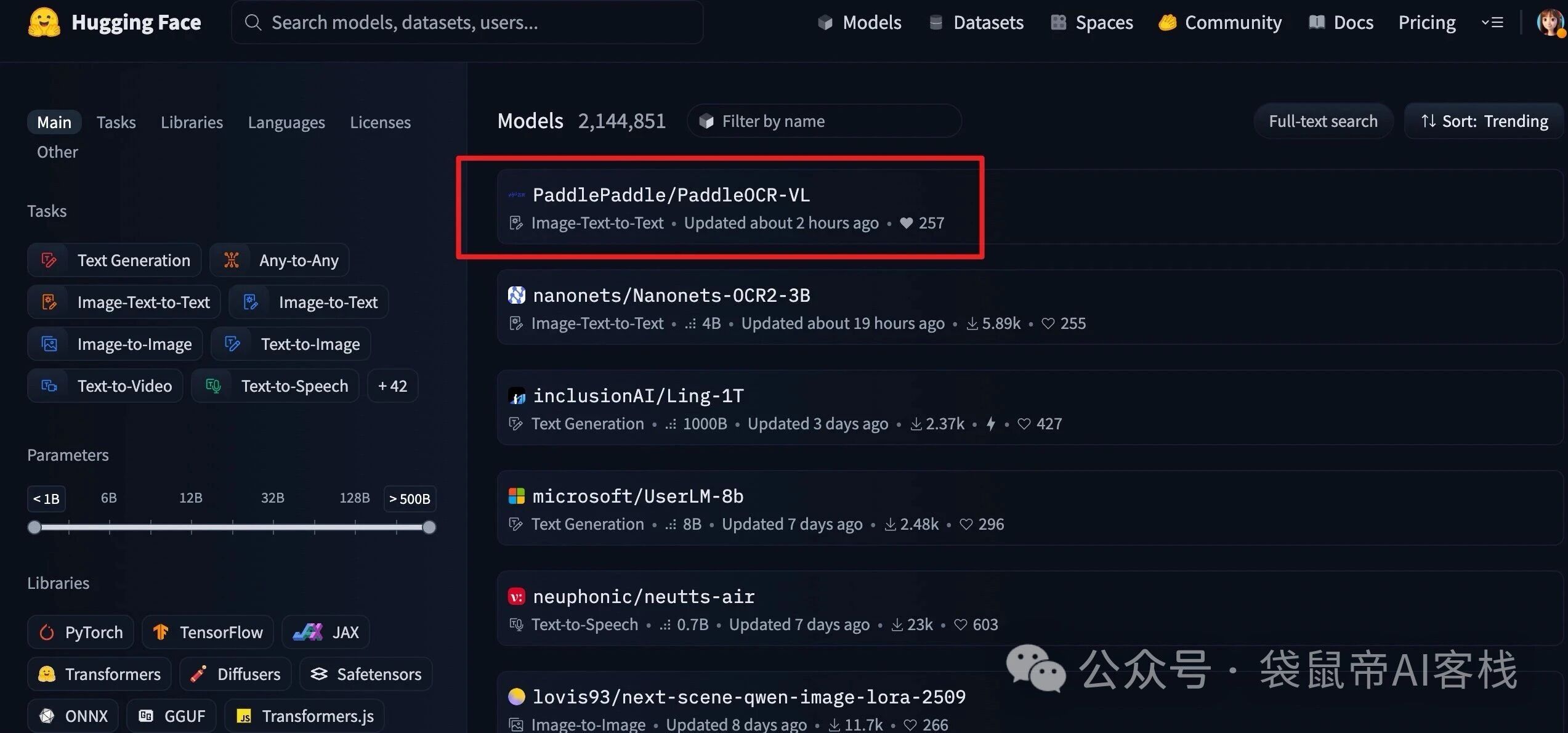
昨晚才发布,今天PaddleOCR-VL就拿下了HuggingFace Trending全球第一
我觉得完全可以用它来拯救那些本地Agent的视觉能力。
以及解决本地AI知识库难以有效果处理多模态文件的问题。
而且这个成本是非常低的。










评论 (0)